


Has your serverless app gotten caught with sluggish supply occasions? Everyone drags, generally. Presenting ephemeral environments and GitHub Actions – the answer you’ve been looking for. In ephemeral environments, you check and deploy your code in remoted environments which are shortly created and destroyed. And through the use of GitHub Actions, you simply automate the deployment course of, making it quicker and extra environment friendly. On this article, you’ll virtually learn to implement them to spice up the supply pace of your serverless apps.
What’s an ephemeral setting and why do you want (greater than) one?
An ephemeral setting is a short-term and disposable setting used to run and check software program purposes. The time period “ephemeral” refers to the truth that these environments are created shortly, used for a short while, after which – poof – destroyed.
The principle benefit of ephemeral environments is their isolation. A single setting is totally separated from the others, which means any modifications made to 1 setting gained’t have an effect on the others. This enables builders to check their code in a protected and managed approach with out worrying about unintended unintended effects.
What’s extra, an ephemeral setting additionally permits for parallelizing the work. Your growth crew consists of many specialists engaged on totally different options on the similar time? Simply spin up a model new ephemeral setting for every function and you might be able to go.
Involved about the price?
Normally creating a number of environments for an utility shortly provides up and considerably slims down the pockets. Not the case with serverless apps! The elemental idea of serverless is “pay for what you employ” – which suggests invoking new assets doesn’t generate any price in any respect. You solely pay for the precise utilization and since these environments are solely used for testing functions (after which disappear), the price is marginal.
Within the case of serverless, many of the dependable assets for constructing the appliance stack, are being created and destroyed faster compared to, for instance, a set of EC2 cases. This significantly reduces the time it takes you to ship software program to prospects, as builders check and deploy their code extra often.
How a few basic native growth strategy?
You’re in all probability considering – “Hey, why don’t we simply do customary native growth? As an alternative of pushing each change to the cloud and testing it there, we may mock cloud providers regionally and check offline, proper?”
Sounds nice in concept, particularly since there are providers specializing in emulating the cloud, like Localstack, as an illustration. I don’t anticipate you to belief some web tech man, so let me persuade you with the facility of arguments. ?
Lack of predictability
For me, one of many best advantages of the cloud is its predictability so long as you employ it at each stage of the event part – `dev`, `staging`, `prod`, you title it. If one thing works on dev, it has to work on `prod` as properly, since you employ the identical providers offered by the cloud operator. No extra “works on my machine, however not in manufacturing.”
I oversimplified a little bit bit. The habits of cloud-managed providers additionally will depend on their configuration. Fortunately, that’s one thing that you would be able to additionally make similar at each stage of the event through the use of IaC (Infrastructure as Code) and CI/CD strategy as an alternative of manually creating the assets.
Through the use of the native growth strategy, you robotically lose that huge profit.
Getting out of sync with the cloud
Cloud suppliers, particularly the massive boys, AWS, Azure, and GCP, develop new stuff day by day. Don’t consider me? Try the AWS bulletins feed. Simply on thirty first March 2023 alone, they someway managed to make eleven new bulletins! ?
With this roadrunner pace of modifications, there is no such thing as a approach for any emulator presently available on the market to be all the time up-to-date and consistent with cloud suppliers. There are some things worse than coping with an outdated model of the service regionally and realizing it solely after deploying the modifications to the cloud.
No 100% service protection
Fast cloud growth means modifications not solely within the present providers but in addition within the fixed flood of recent creations. The identical ol’ story – presently, there’s no single service accessible that would provide 100% service protection. When you check out a model new cloud service that simply got here out or a service that’s been there for a while already, however it’s not but been emulated, you might be at a useless finish.
An actual-life instance from a fintech challenge
Not too long ago, I had an opportunity to work within the fintech trade for a digital financial institution. Sorry for not mentioning the title particularly however we honor and respect NDAs with our companions.
The total case research of our cooperation with the digital financial institution
By creating a wholly new fee course of primarily based on dependable AWS providers, we helped the financial institution develop its portfolio by 4% yearly.
Anyway, the banking software program product itself and the groups accountable for totally different domains began rising quickly, and we entered a part the place we couldn’t successfully ship new functionalities.
Initially, every developer created the brand new stack from scratch or used a shared `dev` setting. That shortly bought out of hand and builders had two decisions: ready for ages in a digital queue to check their work or spending much more time initializing the environments from scratch.
So the primary concept was selecting up Localstack (yup), and attempting out the native growth perspective. We didn’t have to attend lengthy till we realized that the habits of mocked providers differ from the unique ones. Much more problematic for the longer term was progressing growth and rising complexity of our mocked stacks. We had been spending most time attempting to mimic the cloud as an alternative of delivering worth to the shoppers.
That wouldn’t do. After deliberation, we determined to check out ephemeral environments.

Our stacks largely consisted of serverless assets, so establishing ephemeral environments for them went silky clean. Having one thing over ten totally different providers represented by separate CloudFormation stacks with dozens of Lambdas inside and different serverless providers like DynamoDB, S3, and many others., we barely noticed any enhance in our AWS billing. Nearly all of assets that we used throughout all ephemeral environments had been lined by the AWS Free Tier plan. Additionally, developer expertise and the supply tempo visibly elevated since we not needed to battle one another about who ought to deploy and check their stuff first.
Methods to cope with serverful assets?
One of many largest issues when coping with ephemeral environments for serverless is tips on how to strategy the serverful ones. Why will we even care about serverful assets after we are constructing a serverless stack? Nice query! Sadly, life is just not black and white and generally you would possibly nonetheless wish to use serverful assets to perform your wants. As an example, you would possibly wish to use a basic RDS as an alternative of Amazon Aurora Serverless as a relational database. Spinning a model new RDS occasion for every of your new environments is just not the very best concept. RDS is just not solely fairly an costly AWS service, however it additionally wants a while in addition in, which means ephemeral environments take longer to create and delete.
Methods to strategy serverful assets then?
Effectively, I’m not gonna lie that I invented all of it on my own. Meet the superb tech persona who makes a speciality of AWS serverless – Yan Cui, a.okay.a The Burning Monk, AWS Serverless Hero. I strongly advocate testing his weblog publish about dealing with serverful assets, as I’m solely going to briefly summarize his really useful strategy.

If there’s a method to reuse a serverful useful resource, do it.
Spawn an occasion in your AWS account the place you’re going to deploy your ephemeral environments and make the serverless stack use it. If that’s an RDS occasion, simply create a separate database per every setting however throughout the identical RDS occasion. When deleting the stack, simply drop the database to eliminate check information and free the storage.
Let’s create ephemeral environments with GitHub Actions collectively
Starting and the challenge construction
We’re going to create a easy CI/CD answer utilizing GitHub Actions. The concept is to create two pipelines:
- For creating/updating the setting as soon as the pull request is created/up to date by a brand new commit push.
- For eradicating the setting as soon as the pull request is closed or merged.
Though the workflows are fairly easy, we’ll create two customized actions (known as composite actions in Github Actions notation) to simplify and reuse the frequent steps utilized by workflows.
I can be utilizing the SLS framework for deploying my stack and Node.js as a runtime.
The cloud supplier of my alternative can be AWS.
You may see the construction of our `.github` listing under.
The construction of .github listing
Customized GitHub actions
Let’s begin by defining and shortly going by means of our two customized actions.
Setup node motion
The aim of the aforementioned one is to configure our Node.js runtime setting. In each workflows – for creating and destroying the ephemeral environments — we now have to first arrange Node.js to execute SLS instructions.
The motion takes `node_version` as the one enter parameter. Because of it, we are able to reuse the motion with totally different variations of Node.js.
The motion itself is fairly easy, it’s price mentioning caching although. To avoid wasting time (and time is cash, in fact) the motion installs dependencies if and provided that the `node_modules` listing is just not cached or the content material of `package-lock.json` has modified. In every other case, we merely omit the set up of dependencies and reuse the already present ones on the GitHub Actions runner’s working system (discover the `if` assertion on the `Set up dependencies` step).
Get stage title motion
The latter motion is to retrieve the stage title that can be used as a part of our CloudFormation stack. This can be an identifier of our ephemeral setting.
In my case, I named the levels as pull request numbers within the following format: `pr<consecutive-pull-request-number>. Nevertheless, you’re free to implement your personal naming habits, e.g. substitute the PR quantity with the department title in the event you discover it extra significant.
Because of having customized motion, you outline the logic as soon as and reuse it throughout your whole workflows.
To reference the stage title from elsewhere, we now have to export it first – that’s why we save the `stage` parameter to `$GITHUB_OUTPUT` environmental variable after which export it by way of the `outputs` part.
Key issues it’s best to put together upfront
Earlier than you soar into the workflows, there are two issues it’s a must to do upfront.
1. Embrace the stage title in useful resource names
Within the case of the SLS framework, by default, it prefixes all assets with `${self:service}-${self:supplier.stage}` phrase. Make sure you set these values correctly in your `serverless.yml` file. Wherever you wish to give your useful resource a customized title, make sure that all the time to incorporate the service and the stage names, like within the instance under.
Serverless.yml with outlined and referenced service and stage names
This fashion, there can be no conflicts in useful resource names that, generally, should be distinctive. Additionally, by having a constant naming conference, it is going to be simpler to distinguish assets that belong to the identical ephemeral setting.
2. Outline variables and secrets and techniques required for the deployment
Because you’ll be deploying your app to AWS, you must configure some AWS-related and app-related parameters. You are able to do it within the GitHub repository settings beneath the “Secrets and techniques and variables` part.
Secrets and techniques:
- `DEV_AWS_ACCESS_KEY_ID`
- `DEV_AWS_SECRET_ACCESS_KEY`
Variables:
- `APP_NAME`
- `DEV_AWS_ACCOUNT_REGION`
Workflow for creating an ephemeral setting
Lastly, we’re able to outline workflows accountable for invoking and pruning ephemeral environments. Let’s begin with the workflow that creates an ephemeral setting:
So, from high to backside:
Underneath the `on: pull_request` part you might see three varieties: `opened`, `synchronized`, and `reopened`. Because of this each time you create a model new pull request, push a brand new decide to an present one, or reopen an previous pull request, the ephemeral setting can be both created or up to date.
If you need to be taught extra about totally different Pull Request triggers, test our GitHub Actions documentation.
Within the `jobs` part you’ve got two jobs: `run-linter-and-unit-test` and `create-per-feature-environment`.
Earlier than I deploy the stack to the cloud, I prefer to validate it first – that’s the explanation behind the primary job. In my case, that’s only a naked minimal – working code linter and unit checks. You do you because it’s simply adjustable to no matter you want.
The second job performs the precise deployment. Contained in the `deploy` step you solely should go environmental variables – so the serverless framework is aware of the place to deploy – and run `sls deploy` command with the `–stage` parameter set to the worth retrieved from the `get-stage-name` step. That’s it!
Workflow for deleting an ephemeral setting
Now let’s care for deleting the setting when it’s not wanted, i.e. when the pull request will get merged.
Workflow that deletes ephemeral setting
The `on: pull_request” part in all probability doesn’t shock you. Begin with establishing your runtime and putting in all required dependencies with the `setup-node` motion. Subsequent, retrieve the stage title, and eventually,b delete the stack by invoking `sls take away` command. Simple-peasy!
Combine your CI/CD pipeline with GitHub Environments & Deployments
Means to see from the pull request view the standing of your deployment is a helpful function, in the event you ask me. As an alternative of leaping between PR and GitHub Actions tabs, the likelihood to have all the things in a single place is a time saver.
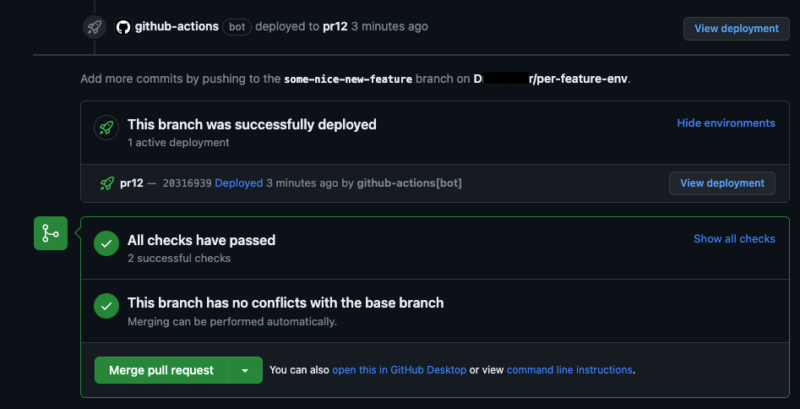
Your life can be simpler with the flexibility to see your whole deployed stacks from the supply code repository system, as an alternative of searching them by means of AWS Console. Particularly in the case of short-term environments, lots of which might exist concurrently.
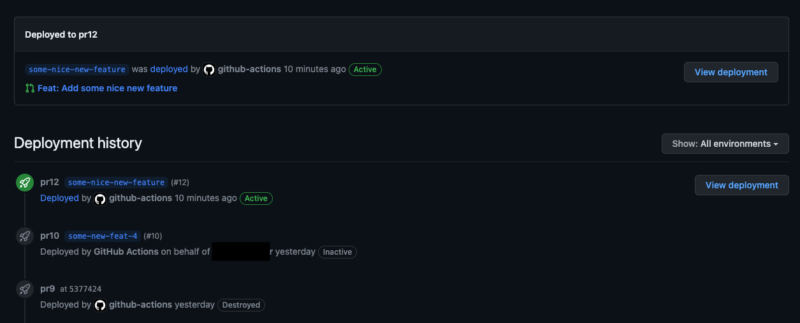
Your secret weapon to combine the pipeline with GitHub Environments and Deployments can be bobheadxi/deployments group motion, which is a wrapper for GitHub Deployments REST API enabling you to handle the deployment statuses out of your CI/CD pipeline.
Earlier than you begin adjusting the workflows, it’s a must to change the permissions for the GitHub token, generated for each workflow (required to vary the deployment standing). By default, the token has solely learn entry for all the scopes, however you can even enable it to write down entry for some/all the actions.
There are two methods to realize it:
- Both give the token all-write permission for all the scopes by way of the repository settings tab, beneath the `Actions` part

Workflow permissions for GitHub token - Or assign granular permission by explicitly assigning permissions to jobs inside your workflow information.
Enhanced creation workflow
Now, let’s modify the prevailing workflow for deploying an ephemeral setting.
Enhanced workflow that creates an ephemeral setting
Three issues have modified right here:
1. Proper earlier than the `deploy` step, we now have added an additional step known as `start-deployment`. By setting `step: begin`, we notify GitHub that the deployment of your setting (with the title from the `get-stage-name` step) has simply began. When you head over to your PR view, you possibly can see an replace on the deployment course of.

Bear in mind to set the `ref` property to `github.head_ref`. By default, the motion makes use of `github.ref` which solely works for `push` occasions. Within the case of `pull_request` occasions, it’s a must to retrieve the commit reference from `github.head_ref` discipline.
2. Within the `deploy` step, the one factor that has modified is the 2 final strains within the `run` part. I hearth a easy AWS CLI command to get my app URI from the CloudFormation stack and export it as `api_uri` which is referenced in a while.
I retrieve the URI of the AWS API Gateway, however you possibly can put no matter you need right here. The URI of AppSync, in the event you construct a serverless GraphQL answer, as an illustration. Or utterly skip this half if the function of navigating to your deployed setting from the GitHub Actions view is just not important for you.
Within the case of the SLS framework, I merely exported the `ApiUri` as an output variable like under.
Export of ApiUri
The `finalize-deployment` step has been added, proper after the `deploy` one. Right here, you mark the deployment as completed and set its standing in accordance with the job standing. If the earlier step failed, the deployment can be marked as a failure and the earlier one can be endured. If it succeeded, the earlier setting can be overwritten with the brand new one. As well as, you can even set `deployment_id` to the worth from the `start-deployment` step, so GitHub is aware of which deployment id this pipeline refers to. Lastly, specify the `env_url` that you simply exported earlier.
Enhanced deletion workflow
Your deployment workflow has already been adjusted, now let’s shortly alter the one used to destroy the ephemeral setting (used for an correct overview of all of your environments).
Enhanced workflow that deletes ephemeral setting
The one factor that has modified right here is the addition of the `Deactivate setting` step proper after the stack will get deleted. By specifying `step: delete-env` you utterly eliminate the deleted setting, which means it is going to be not seen within the GitHub environments part.
I choose this strategy in the direction of ephemeral environments as a result of as soon as they get deleted I don’t care about them anymore. When you choose to maintain them however mark them as `Inactive`, change the worth of `step` to `deactivate-env`.
Congratulations, you’ve simply constructed an entire CI/CD answer for deploying serverless ephemeral environments with the assistance of GitHub Actions! ?
Seed. A zero-configuration different
Though setting your personal CI/CD answer for the serverless app is just not rocket science, generally you simply wish to delegate it to an exterior vendor and give attention to one thing else. Right here is the place Seed turns out to be useful. This isn’t a paid promotion – I found Seed not so way back and it made a reasonably good impression on me. Possibly by means of my article, anyone else will discover this different engaging.
![]()
The identical crew accountable for the SST framework, developed Seed – a mixture of a zero-configuration CI/CD pipeline for a serverless app and a real-time Lambda alerting and monitoring device. It really works just about out of the field after connecting the supply code repository and passing AWS credentials to it.
If you wish to experiment with customized stuff in your CI/CD pipeline, Seed allows it by way of a customized file named `seed.yml` – you describe the steps that can be executed on the particular phases of the pipeline course of.
What’s cool about Seed is the truth that enabling the function of ephemeral environments to your PRs or new branches is only a matter of some clicks. Check out the picture under – that’s all you must do.
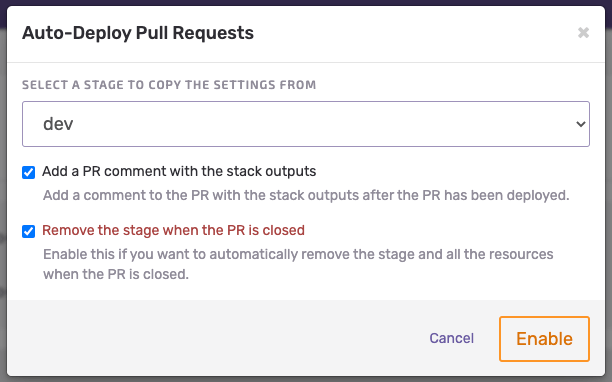
One final function of Seed that caught my consideration is incremental deployments. Within the case of a monorepo with a number of CloudFormation stacks, Seed deploys solely the stack that modified, with out performing any operations on the stacks that didn’t. There may be additionally an possibility so as to add incremental deployments on the Lambda stage, so as an alternative of deploying the entire stack, Seed merely replaces Lambda’s zip packages. Nevertheless, on the time of writing, the function continues to be in beta model and it’s only accessible for the SLS framework.
Within the case of Seed’s drawbacks, for me, the most important ones are:
- The dearth of assist for different serverless frameworks than SST and SLS, like AWS SAM.
- The principle focus as a supply code repository was positioned on GitHub. Bitbucket and GitLab are additionally supported, however they lack some options that GitHub has.
- When CI/CD course of is comparatively advanced, it’s higher to personal and handle your customized CI/CD pipeline to realize extra flexibility quite than vendor-locking yourselves with Seed.
I extremely advocate testing Seed and deciding if it matches together with your subsequent challenge. If I had been to decide on, I might say that after I don’t care about vendor-locking myself to some exterior CI/CD supplier, the challenge solely requires some comparatively easy CI/CD course of and I’m in a rush, I might think about Seed as an possibility. In different circumstances, I’d in all probability keep on with CI/CD options which are extra mature, like GitHub Actions, BB Pipelines, and many others.
Execs and cons of utilizing ephemeral environments
Advantages of ephemeral environments
One of many essential benefits ephemeral environments present is a extra agile growth course of. With the flexibility to shortly spin up new environments, builders can simply check out new options and modifications with out worrying about disrupting present techniques. This will result in quicker iterations and a extra environment friendly growth course of general.
- enabling builders to work successfully, testing their code independently from different crew members,
- testing and accepting options in isolation by High quality Assurance is a lot simpler,
- compatibility with agile software program growth,
- no disruption to already-existing techniques,
- shortening Time to Supply of options.
Disadvantages of ephemeral environments
As with most issues in software program growth, ephemeral environments aren’t any one-size-fits-all answer for all the things. One of many disadvantages of utilizing ephemeral environments is the fixed want for an web connection to do any motion. That’s a minor concern for me – I can’t recall the final time I haven’t had an web connection at work. The identical story goes for downloading an exterior bundle required to your challenge – in case you are offline, you merely can’t (until you’ve got it saved someplace in your laptop’s reminiscence which is a reasonably uncommon commodity).
One other disadvantage is the limitations of a single AWS account. A few of these limits might be elevated in the event you attain out to AWS assist, however others are fastened and can’t be exceeded. For instance, the utmost variety of Lambda features you possibly can deploy to a single area is 1,000 (this restrict might be raised upon request). Nevertheless, arduous limits can’t be exceeded, e.g. the utmost of 500 AWS Step Capabilities state machines allowed in a single area. Whereas these limits are usually excessive and arduous to achieve, it’s nonetheless essential to be conscious of them. To keep away from hitting these limits, it’s really useful to merge pull requests promptly and often, not only for ephemeral environments but in addition as a common finest follow. If a number of options stay unmerged for every week you in all probability don’t have to preserve a separate setting for them.
- configuring overhead whereas setting the environments up,
- needing a secure web connection always,
- little or no price enhance for every of the environments’ infrastructure.
Short-term environments on-demand
Utilizing ephemeral environments could be a highly effective device for enhancing the supply pace of your serverless purposes. With the assistance of CI/CD options, creating and deleting disposable environments on the fly is straightforward and ensures consistency throughout deployments.
I like to recommend giving ephemeral environments a attempt, particularly in larger initiatives, just like the aforementioned banking platform that was working in a couple of nations and in numerous currencies.
From a software program engineer’s perspective, the flexibility of testing options in isolation, even when different individuals concurrently labored on the identical challenge, was a large benefit.
From a enterprise perspective, we managed to ship issues so much faster than earlier than. Because the deadlines had been tight, ephemeral environments offered us with the rocket enhance that we wanted to efficiently end all jobs in time.
In our case, it was a win-win state of affairs. I hope you will discover them as a lot helpful as we did in your subsequent enterprise.
Mounted deadlines are looming over your challenge? Our individuals will assist
You’ve got little to no time to recruit further builders for the job, accomplice up with TSH and complement your crew with world-class, AWS-certified specialists.
Click on under and inform us about your drawback. We’ll get again to you with a 1-hour session, freed from cost.























{kind=link}