


This job processes hundreds of thousands of occasions day by day from two major knowledge sources and 4 completely different enrichment sources, calculates cross-charge quantities with becoming a member of sources after which publishing the outcomes to an output Pub/Sub. Moreover, all output messages are endured in Google BigQuery for additional evaluation and reporting.
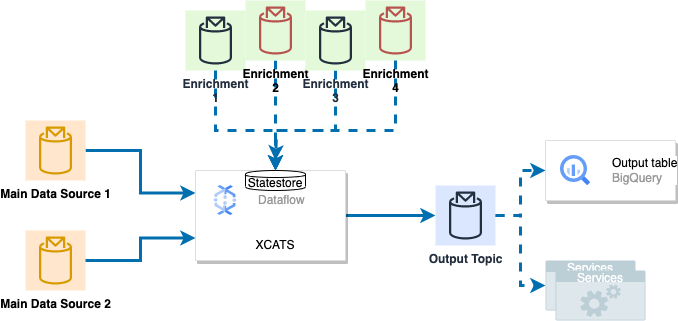
As the dimensions of our knowledge grew, we began encountering efficiency bottlenecks and inefficiencies in our processing pipeline.
We are going to share our expertise with optimizing certainly one of our enrichment strategies, lowering the processing time for one move from 1 day to only half-hour. We may also present pattern code for each the previous and new algorithms in Java and present how this variation impacted our CPU and Reminiscence utilizations and total efficiency.
Downside
In our dataflow pipeline, we have been integrating a small enrichment supply. Our preliminary technique concerned utilizing Apache Beam’s State and CoGroupByKey to pair this small dataset with the primary knowledge flows. Nonetheless, this technique introduced some crucial points.
Downside: The pipeline was sluggish, taking a full day to course of knowledge, and the appliance was expensive. The inefficiency was not solely when it comes to processing energy however moderately within the financial sense, making it an costly resolution to take care of. Inefficiency not solely poses and financial burden but in addition has implications for the setting, making it an unsustainable resolution in the long term.
Root Trigger: This inefficiency was primarily as a result of a basic Stream Processing pitfall referred to as Information Skew and Excessive Fan-out. The appliance of Apache Beam’s State and CoGroupByKey in our pipeline induced key partitions with a sparse variety of key-value pairs to be assigned to a single employee. As our system was inundated with hundreds of thousands of occasions, this lone employee rapidly turned a bottleneck, resulting in important inner and exterior backlogs.
Regardless of a rise within the variety of staff to the utmost permitted, their CPU and reminiscence utilization remained surprisingly low. This indicated that our processing methodology was inefficient, because it was not optimally using obtainable assets.
The next screenshot additional illustrates the efficiency bottleneck of one of many associated processes:
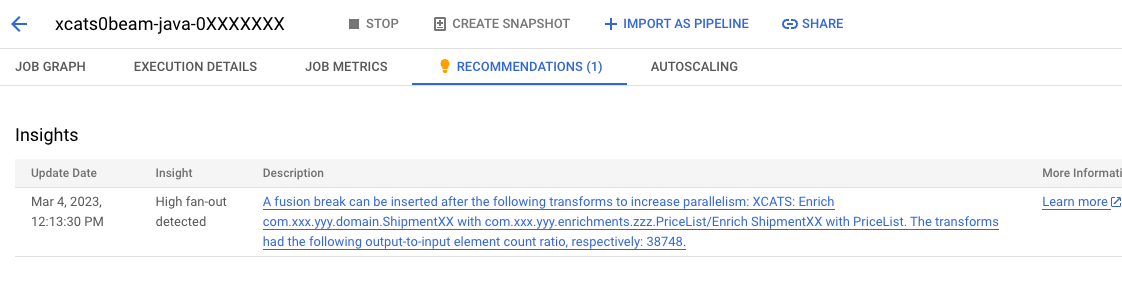
Previous Algorithm: Utilizing CoGroupByKey
Here is a pattern code snippet(with out state element)for our authentic strategy utilizing CoGroupByKey in Java (For manufacturing resolution we use Stateful processing):
public class OldAlgorithm {
public static void major(String[] args) {
// Create the pipeline
Pipeline pipeline = ...
// Learn the primary knowledge from Pub/Sub subject
PCollection<String> mainDataInput = pipeline.apply("Learn Foremost Information",
PubsubIO.readStrings().fromTopic("tasks/YOUR_PROJECT_ID/subjects/YOUR_MAIN_DATA_TOPIC"));
// Course of the primary knowledge and convert it to a PCollection of KV<String, MainData>
PCollection<KV<String, MainData>> mainDataFlow = mainDataInput.apply("Course of Foremost Information", ParDo.of(new MainDataParser()));
// Learn the small enrichment knowledge from Pub/Sub
PCollection<String> smallEnrichmentInput = pipeline.apply("Learn Small Enrichment Information", PubsubIO.readStrings().fromTopic(
"tasks/YOUR_PROJECT_ID/subjects/YOUR_SMALL_ENRICHMENT_TOPIC"));
// In manufacturing code we use Apache Beam State function for this enrichment, and we had saved it in state, so we did not have to reread from the supply once more
// Course of the small enrichment knowledge and convert it to a PCollection of KV<String, SmallEnrichmentData>
PCollection<KV<String, SmallEnrichmentData>> smallEnrichmentSource = smallEnrichmentInput.apply("Course of Small Enrichment Information",
ParDo.of(new SmallEnrichmentParser()));
// Outline TupleTags for CoGroupByKey
TupleTag<MainData> mainDataTag = new TupleTag<>();
TupleTag<SmallEnrichmentData> smallEnrichmentTag = new TupleTag<>();
// Carry out CoGroupByKey on major knowledge move and small enrichment supply
PCollection<KV<String, CoGbkResult>> joinedData = KeyedPCollectionTuple.of(mainDataTag, mainDataFlow)
.and(smallEnrichmentTag, smallEnrichmentSource)
.apply(CoGroupByKey.create());
// Outline a DoFn to course of the joined knowledge
class ProcessJoinedDataFn extends DoFn<KV<String, CoGbkResult>, EnrichedData> {
personal closing TupleTag<MainData> mainDataTag;
personal closing TupleTag<SmallEnrichmentData> smallEnrichmentTag;
public ProcessJoinedDataFn(TupleTag<MainData> mainDataTag, TupleTag<SmallEnrichmentData> smallEnrichmentTag) {
this.mainDataTag = mainDataTag;
this.smallEnrichmentTag = smallEnrichmentTag;
}
@ProcessElement
public void processElement(ProcessContext context) {
KV<String, CoGbkResult> factor = context.factor();
String key = factor.getKey();
Iterable<MainData> mainDataList = factor
.getValue()
.getAll(mainDataTag);
Iterable<SmallEnrichmentData> smallEnrichmentDataList = factor.getValue().getAll(smallEnrichmentTag);
// Course of the joined knowledge and output EnrichedData situations
for (MainData mainData : mainDataList) {
for (SmallEnrichmentData smallEnrichmentData : smallEnrichmentDataList) {
EnrichedData enrichedData = new EnrichedData(mainData, smallEnrichmentData);
context.output(enrichedData);
}
}
}
}
// Course of the joined knowledge
PCollection<EnrichedData> enrichedData = joinedData.apply("Course of Joined Information", ParDo.of(new ProcessJoinedDataFn(mainDataTag, smallEnrichmentTag)));
// Write the enriched knowledge to the specified output, for instance, to a file or a database
// Run the pipeline
pipeline.run().waitUntilFinish();
}
}New Algorithm: Utilizing SideInput and DoFn capabilities
After cautious evaluation of our knowledge processing wants and necessities, we determined to make use of the Apache Beam SideInput function and DoFn capabilities to optimize our Google DataFlow job. SideInput, for these unfamiliar, is a function that enables us to usher in further knowledge, or ‘enrichment’ knowledge, to the primary knowledge stream throughout processing. That is significantly useful when the enrichment knowledge is comparatively small, because it’s then extra environment friendly to convey this smaller dataset to the bigger major knowledge stream, moderately than the opposite means round.
In our case, the first motive behind this determination was the character of our enrichment dataset. It’s comparatively small, with a dimension of lower than 1 GB in reminiscence, and doesn’t change steadily. These traits make it an ideal candidate for the SideInput strategy, permitting us to optimize our knowledge processing by lowering the quantity of information motion.
To additional enhance effectivity, we additionally transitioned our enrichment dataset supply from a streaming subject to a desk. This determination was pushed by the truth that our dataset is a slow-changing exterior dataset, and as such, it is extra environment friendly to deal with it as a static desk that will get up to date periodically, moderately than a steady stream. To make sure we’re working with probably the most up-to-date knowledge, we launched a time ticker with GenerateSequence.from(0).withRate(1, Period.standardMinutes(60L)) to learn and refresh the info each hour.
Code:
public class NewAlgorithm {
public static void major(String[] args) {
// Create the pipeline
Pipeline pipeline = Pipeline.create(choices);
// Learn the primary knowledge from Pub/Sub subject
PCollection<String> mainDataInput = pipeline.apply("Learn Foremost Information",
PubsubIO.readStrings().fromTopic("tasks/YOUR_PROJECT_ID/subjects/YOUR_MAIN_DATA_TOPIC"));
// Course of the primary knowledge and convert it to a PCollection of MainData
PCollection<MainData> mainDataFlow = mainDataInput.apply("Course of Foremost Information", ParDo.of(new MainDataParser()));
// Generate sequence with a time ticker
PCollection<Lengthy> ticks = pipeline.apply("Generate Ticks", GenerateSequence.from(0).withRate(1, Period.standardMinutes(60L)));
// Learn the small enrichment knowledge from BigQuery desk
PCollection<SmallEnrichmentData> smallEnrichmentSource = ticks.apply("Learn Small Enrichment Information",
BigQueryIO.learn().from("YOUR_PROJECT_ID:YOUR_DATASET_ID.YOUR_TABLE_ID")
.usingStandardSql().withTemplateCompatibility()
.withCoder(SmallEnrichmentDataCoder.of()));
// Generate a PCollectionView from the small enrichment knowledge
PCollectionView<Iterable<SmallEnrichmentData>> smallEnrichmentSideInput = smallEnrichmentSource.apply("Window and AsIterable", Window.into(
FixedWindows.of(Period.standardHours(1)))).apply(View.asIterable());
// Outline a DoFn to course of the primary knowledge with the small enrichment knowledge
public static class EnrichMainDataFn extends DoFn<MainData, EnrichedData> {
personal closing PCollectionView<Iterable<SmallEnrichmentData>> smallEnrichmentSideInput;
public EnrichMainDataFn(PCollectionView<Iterable<SmallEnrichmentData>> smallEnrichmentSideInput) {
this.smallEnrichmentSideInput = smallEnrichmentSideInput;
}
@ProcessElement
public void processElement(ProcessContext context) {
MainData mainData = context.factor();
Iterable<SmallEnrichmentData> smallEnrichmentDataList = context.sideInput(smallEnrichmentSideInput);
// Course of the primary knowledge and small enrichment knowledge and output EnrichedData situations
for (SmallEnrichmentData smallEnrichmentData : smallEnrichmentDataList) {
EnrichedData enrichedData = new EnrichedData(mainData, smallEnrichmentData);
context.output(enrichedData);
}
}
}
// Course of the primary knowledge with the small enrichment knowledge
PCollection<EnrichedData> enrichedData = mainDataFlow.apply("Enrich Foremost Information", ParDo.of(new EnrichMainDataFn(smallEnrichmentSideInput))
.withSideInputs(smallEnrichmentSideInput));
// Write the enriched knowledge to the specified output,
}
}Take a look at Case:
To guage the effectiveness of our optimization efforts utilizing the Apache Beam SideInput function, we designed a complete take a look at to check the efficiency of our previous and new algorithms. The take a look at setup and dataset particulars are as follows:
1. We printed 5 million information to a Pub/Sub subject, which was used to refill the Apache Beam ValueState within the job for stream to stream be a part of.
2. We created a small desk containing the enrichment dataset for small enrichment. Previous algorithm makes use of ValueState and new algorithm makes use of SideInput function.
3. We then used 5 million supply information to generate the output for each the previous and new jobs. You will need to word that these supply information inflate within the utility, leading to a complete of 15 million information that should be processed.
4. For our Google DataFlow jobs, we set the minimal variety of staff to 1 and the utmost variety of staff to fifteen.
Outcomes
We are going to study the influence of our optimization efforts on the variety of staff and CPU utilization in our Google DataFlow jobsby evaluating two screenshots taken throughout the first hour of job execution, we will achieve insights into the effectiveness of our previous algorithms with out SideInput versus the brand new implementation utilizing SideInput.
Screenshot 1: Previous Algorithm with out SideInput
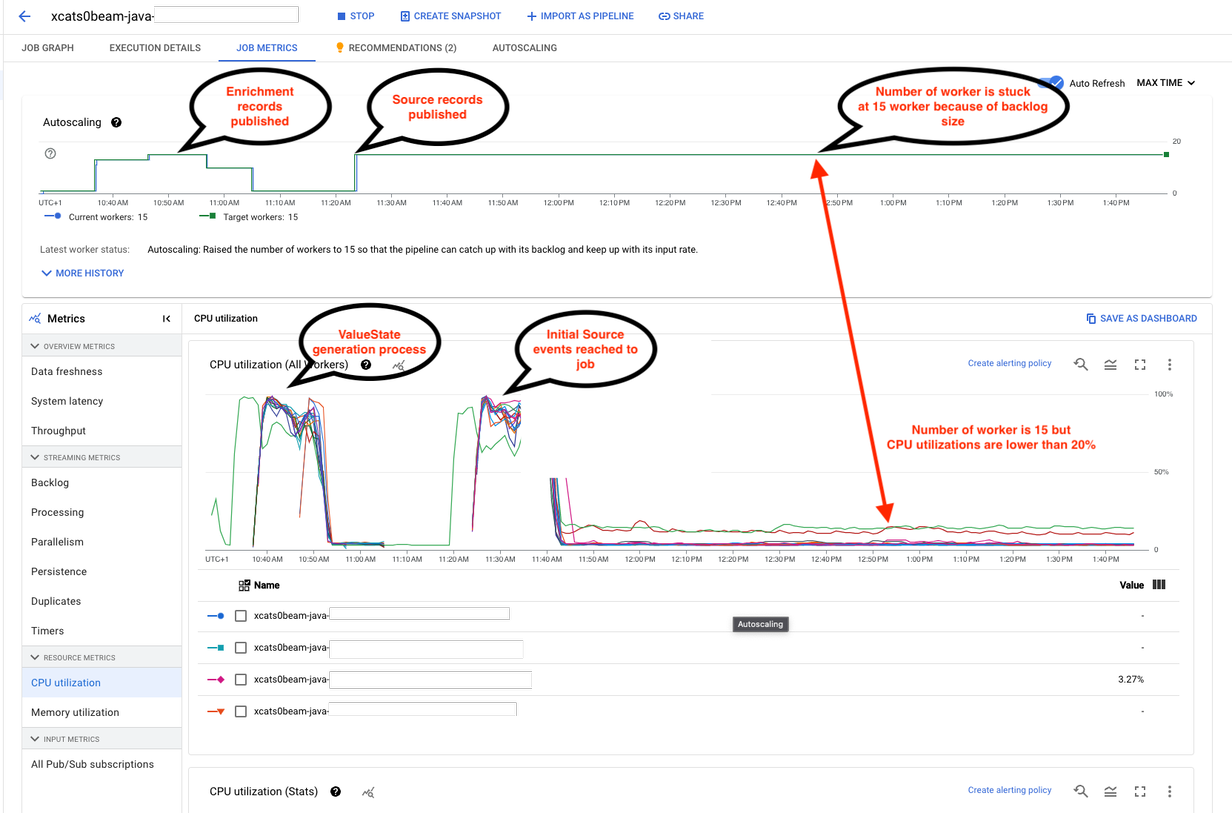
This screenshot shows the efficiency of our previous algorithm, which didn’t make the most of the Apache Beam SideInput function. On this situation, we observe low CPU utilization regardless of having 15 staff deployed. These staff have been caught, a consequence of the auto scale function supplied by Google DataFlow, which relies on backlog dimension.
Screenshot 2: New Algorithm with SideInput
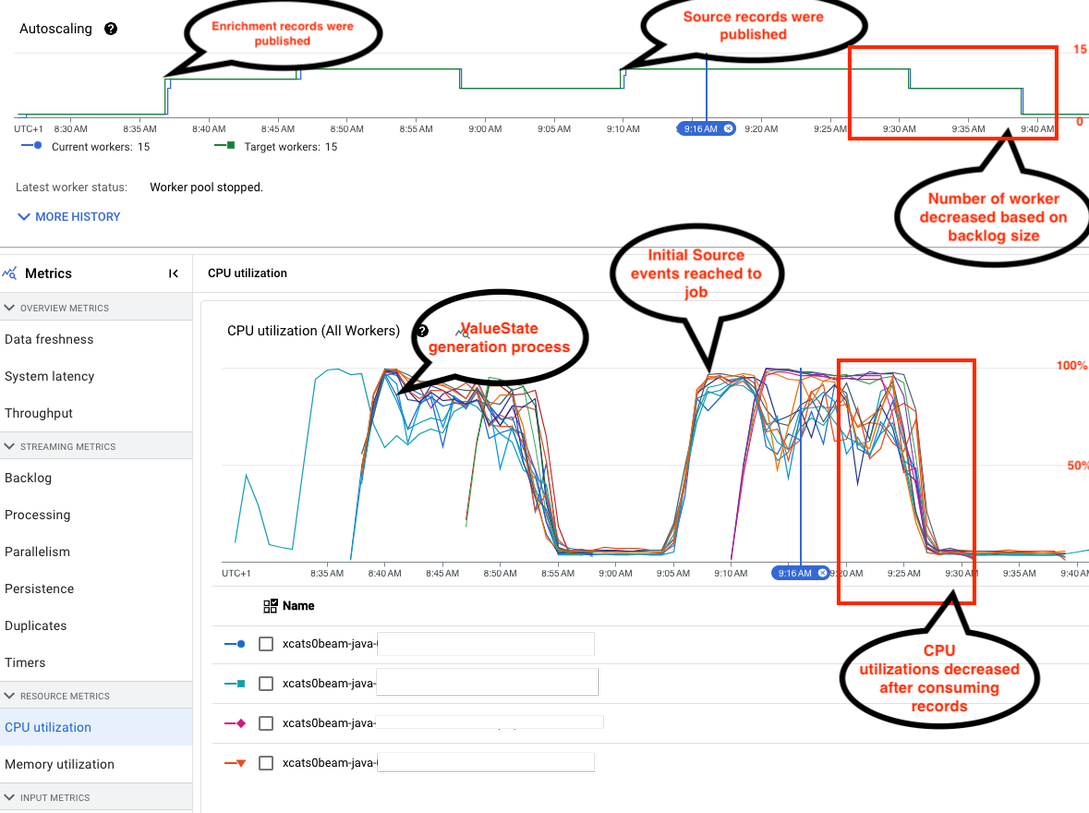
The second screenshot shows the efficiency of our new algorithms, which leverage the SideInput function. On this case, we will see that the DataFlow job is utilizing excessive CPU when new occasions are acquired. Moreover, the utmost variety of staff is just utilized quickly, indicating a extra environment friendly and dynamic allocation of assets.
To exhibit the influence of our optimization, we have in contrast the metrics of the previous job (with out SideInput) and the brand new job (with SideInput). The desk under exhibits an in depth comparability of those metrics:
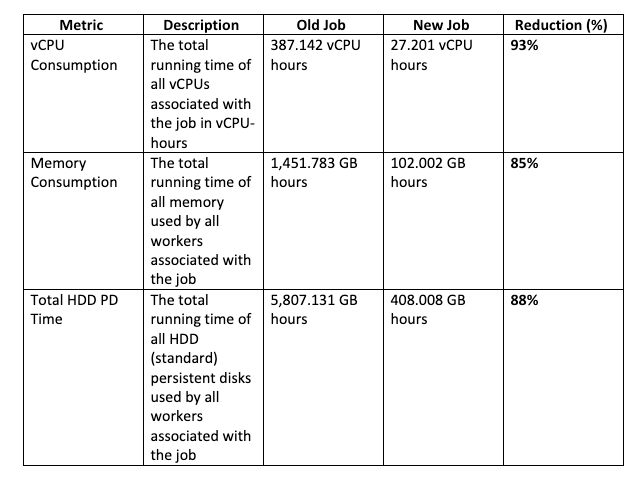
These metrics exhibit spectacular reductions in vCPU consumption, reminiscence utilization, and HDD PD time, highlighting the effectiveness of our optimization. Please discuss with the ‘Useful resource Metrics Comparability’ picture for extra particulars.
Useful resource Metrics Comparision:

The substantial enhancements in these key metrics spotlight the effectiveness of utilizing the Apache Beam SideInput function in our Google DataFlow jobs. Not solely do these optimizations result in extra environment friendly processing, however in addition they end in important value financial savings for our knowledge processing duties
In our earlier implementation with out using SideInput, the job took greater than roughly 24 hours to finish, however the brand new job with SideInput was accomplished in about half-hour, so the algorithm has resulted in a 97.92% discount within the execution interval.
In consequence, we will preserve excessive efficiency whereas minimizing the fee and complexity of our knowledge processing duties.
Warning: Utilizing SideInput for Massive Datasets
Please bear in mind that utilizing SideInput in Apache Beam is really useful just for small datasets that may match into the employee’s reminiscence. The overall quantity of information that ought to be processed utilizing SideInput mustn’t exceed 1 GB.
Bigger datasets may cause important efficiency degradation and should even end in your pipeline failing as a result of reminiscence constraints. If it is advisable course of a dataset bigger than 1 GB, take into account various approaches like utilizing CoGroupByKey, partitioning your knowledge, or utilizing a distributed database to carry out the required be a part of operations. All the time consider the scale of your dataset earlier than deciding on utilizing SideInput to make sure environment friendly and profitable processing of your knowledge.
Conclusion
By switching from CoGroupByKey to SideInput and utilizing DoFn capabilities, we have been in a position to considerably enhance the effectivity of our knowledge processing pipeline. The brand new strategy allowed us to distribute the small dataset throughout all staff and course of hundreds of thousands of occasions a lot quicker. In consequence, we lowered the processing time for one move from 1 days to only half-hour. This optimization additionally had a constructive influence on our CPU utilization, guaranteeing that our assets have been used extra successfully.
In the event you’re experiencing comparable efficiency bottlenecks in your Apache Beam dataflow jobs, take into account re-evaluating your enrichment strategies and exploring choices equivalent to SideInput and DoFn to spice up your processing effectivity.
Thanks for studying this weblog. In case you have any additional questions or if there’s anything we will help you with, be at liberty to ask.
On behalf of Group 77, Hazal and Eyyub
Some helpful hyperlinks:
** Google Dataflow
** Apache Beam
** Stateful processing























{kind=link}