


An organization from a publishing enterprise aimed to make use of AI to investigate its content material and increase inclusivity, particularly for underrepresented girls of their business. By specializing in extracting names and genders from textual content, the mission supplied data-driven insights to drive engagement amongst numerous audiences. Rigorous testing of AI options, together with Google Vertex AI, GPT-3.5 Turbo, and spaCy, helped determine probably the most correct and cost-effective toolset, highlighting AI’s potential in content material evaluation.
Venture background. AI for the publishing business
This mission was performed for media publishers (NDA).
The consumer’s mission was to welcome and cater to girls not so broadly represented of their present content material. The journal wanted an evaluation device to determine widespread content material amongst girls and evaluate the outcomes with analytical information.
The crucial problem on this textual content evaluation was to discern whether or not the textual content predominantly centered on girls or males. To deal with this want, we sought a ready-to-use device that would successfully extract people from the textual content and precisely decide their gender. Finally, the outcomes will function data-driven enterprise insights for knowledgeable selections, driving gross sales amongst girls (and later, different goal teams).
Enterprise necessities
Our companion’s objective was to determine folks within the textual content and acknowledge their gender precisely to realize automated large information for future selections relating to their progress.
The mission aimed to create a classy AI analytics device for publishers, drawing a various viewers and uncovering progress strategies. Utilizing superior algorithms and machine studying, it analyzes content material for biases, enabling the creation of inclusive materials. The platform supplies actionable insights on viewers interactions with content material, suggesting methods to enhance attain and engagement.

Synthetic Intelligence & Pure Language Processing
Given the character of the duty, we opted for a device using Synthetic intelligence (AI), particularly NLP (Pure Language Processing).
NLP is a department of synthetic intelligence specializing in the interplay between computer systems and human language. Growing algorithms and fashions that allow machines to know, interpret, and generate human-like textual content.
NLP expertise is essential for:
- language translation,
- sentiment evaluation,
- textual content summarization,
- speech recognition.
Within the context of our job, using NLP means harnessing superior strategies to boost human speech evaluation. Such capabilities make deciphering and extracting significant insights from human language considerably simpler.
Massive Language Mannequin (LLM)
LLM is a pc program designed to grasp and produce human language successfully. This superior type of synthetic intelligence has undergone complete coaching to boost its skill to know and generate textual content.
LLMs are versatile instruments for:
- textual content composition,
- query answering,
- language translation.
Names extraction. Analyzing accessible instruments (so that you don’t must)
Step one is all the time thorough market evaluation – this time, we’re in search of instruments that find folks’s names in written textual content and work out the gender of these folks talked about.
We divided our evaluation into two elements:
- Extracting people from the textual content.
- Recognizing gender based mostly on first and final names.
For testing, we picked numerous articles, some in English and a few in different languages, to see how effectively these instruments discover names in precise publications.
Compromise
![]()
Compromise is an NLP JavaScript library accessible on GitHub, designed to facilitate straightforward and environment friendly textual content processing in understanding pure language. It supplies a spread of highly effective options, together with tokenization, stemming, part-of-speech tagging, and named entity recognition.
With its user-friendly syntax and complete performance, Compromise is a invaluable device for builders looking for to investigate and manipulate textual information in JavaScript functions, making it notably helpful for duties comparable to language parsing, sentiment evaluation, and knowledge extraction.
Compromise was our first selection as a result of it’s free, you possibly can run it within the Node runtime, and the implementation is easy and quick. Within the first model, we used it as a device for identify extraction and gender recognition.
Let’s begin with an instance:
And the result’s:
Generally, Compromise returned two people in a single object separated by a comma or duplicated people (for instance, Lisa and Lisa). Easy methods to deal with these duplicates?
After eradicating these duplicates, the response seems tremendous, nevertheless it cuts some outcomes (if solely firstName or secondName is talked about).
As you will notice in subsequent research, compromise struggled with a bigger variety of people and infrequently failed to acknowledge all folks appropriately. We determined to strive completely different suppliers.
Google Vertex AI
![]()
To check well-known AIs, we would have liked to look into Google Vertex AI. We used the gemini-1.0-pro-001 language mannequin.
Google Vertex AI streamlines the E2E machine studying workflow, offering instruments and companies for information preparation, mannequin coaching, and deployment duties. It consists of pre-built fashions, automated machine-learning capabilities, and instruments for collaboration, making it a flexible resolution.
Nevertheless, regardless of having different GCP merchandise within the mission, the consumer couldn’t use Google Vertex for authorized causes.
GPT-3.5 Turbo (OpenAI)
![]()
GPT-3.5 Turbo fashions perceive and generate pure language or code. I couldn’t assist however marvel about its accuracy, so I examined this widespread and comparatively straightforward device.
A very powerful factor is to write down the proper immediate, and mine went like this:
And the response:
GPT-4 (OpenAI)
![]()
The principle distinction between the GPT-3.5 Turbo and GPT-4 is the variety of parameters (parts containing the knowledge acquired by the mannequin via its coaching information):
- GPT-3.5 has 175 billion parameters,
- GPT-4 has approx.1 trillion parameters.
An API name with the given physique:
One name is dependent upon the article’s size. It was between 500 and 1500 tokens:
- GPT-3.5 Turbo prices $0,0090 per 1k tokens,
- GTP-4 prices $0,09 per 1k tokens.
The pricing is updated as of February 2024 and is altering quickly. The most recent pricing may be discovered right here: https://openai.com/pricing
So GPT-4 is 10 instances dearer! Should you don’t prioritize increased accuracy with GPT-4, it’s higher to make use of GPT-3.5-turbo. The distinction in value just isn’t proportional to the accuracy.
spaCy JS
![]()
SpaCy is a NLP library and toolkit for Python. It supplies pre-trained fashions and environment friendly instruments for duties comparable to tokenization, part-of-speech tagging, named entity recognition, and extra.
Few libs permit operating spaCy in a Node surroundings, e.g., spacy-js. To hurry it up, we ran it in Python with Nvidia GPU. As an HTTP server, we used Flask.
Utilizing the documentation instance under, we examined the preferred spaCy fashions.
After a couple of checks, we determined to strive SpanMarker. It permits the usage of pre-trained SpanMarker and coaching your mannequin.
Instance span marker implementation:
Now, probably the most thrilling half, you possibly can join these two fashions utilizing spaCy within the following method:
This code makes use of the SpaCy library and a pre-trained transformer-based English language mannequin (en_core_web_trf). Moreover, it provides a customized pipeline element, span_marker, which is loaded from the mannequin with the identify lxyuan/span-marker-bert-base-multilingual-cased-multinerd.
That is solely a fraction of the options accessible in the marketplace. So, let’s begin testing them on genuine articles.
Exams in follow
Articles we used
For comparability, we took a wide range of on-line articles (it’s a unique batch than the unique one, we use completely different examples for instance the technical course of):
- customary English with a lot of folks talked about (The Impartial),
- English from Center Japanese medium with African names and surnames (AlJazeera),
- Polish final take a look at with a soccer league article (Dziennik Zachodni),
- Croatian final take a look at with a soccer league article (Jutarnjeg).
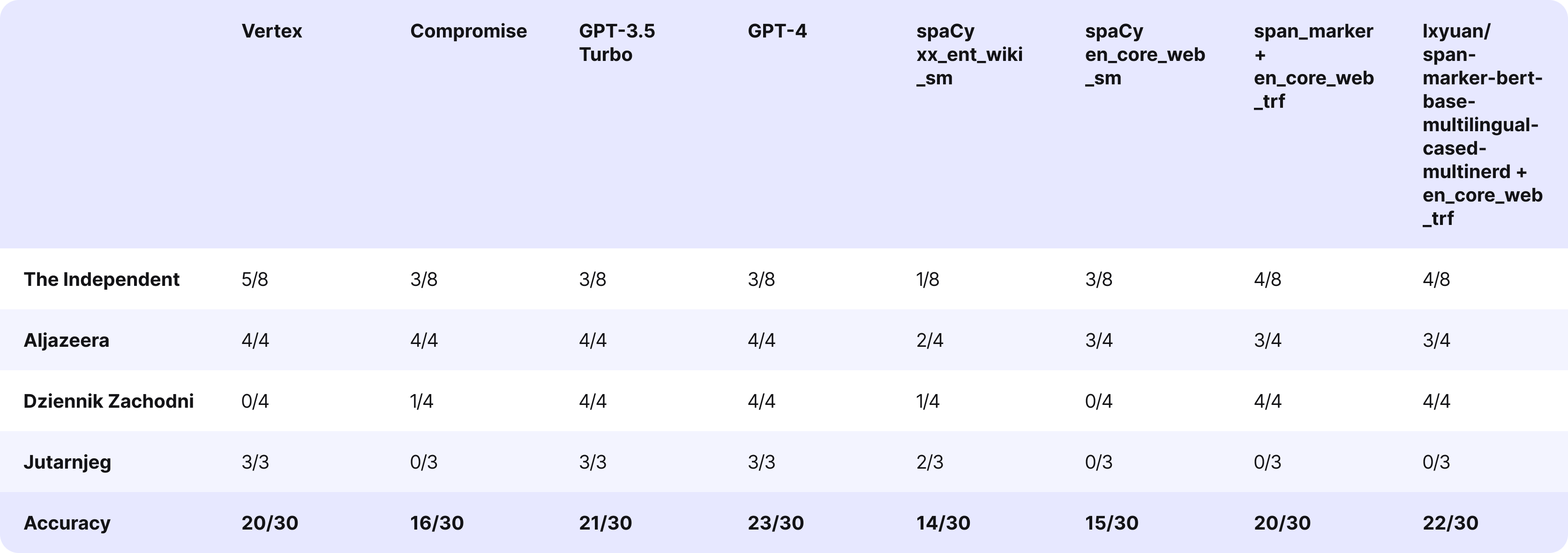
Moreover, we performed an identical factor with this text from The New York Occasions.
Firstly, we learn the article and manually discovered the names. Then, we used instruments to do the identical factor for me. You possibly can take a look at the outcomes under:
Folks talked about within the textual content:
- William of Orange
- Daniel Defoe
- Nikki Haley
- Joe Biden
- Donald Trump
- Eugene V. Debs
- Stormy Daniels
- Mollie Hemingway
- Tim Scott
- Liz Cheney
- William III of England
Now, let’s see how the instruments carried out. For the appropriately acknowledged individual, we add +1 level; for lacking an individual, we deduct -1.
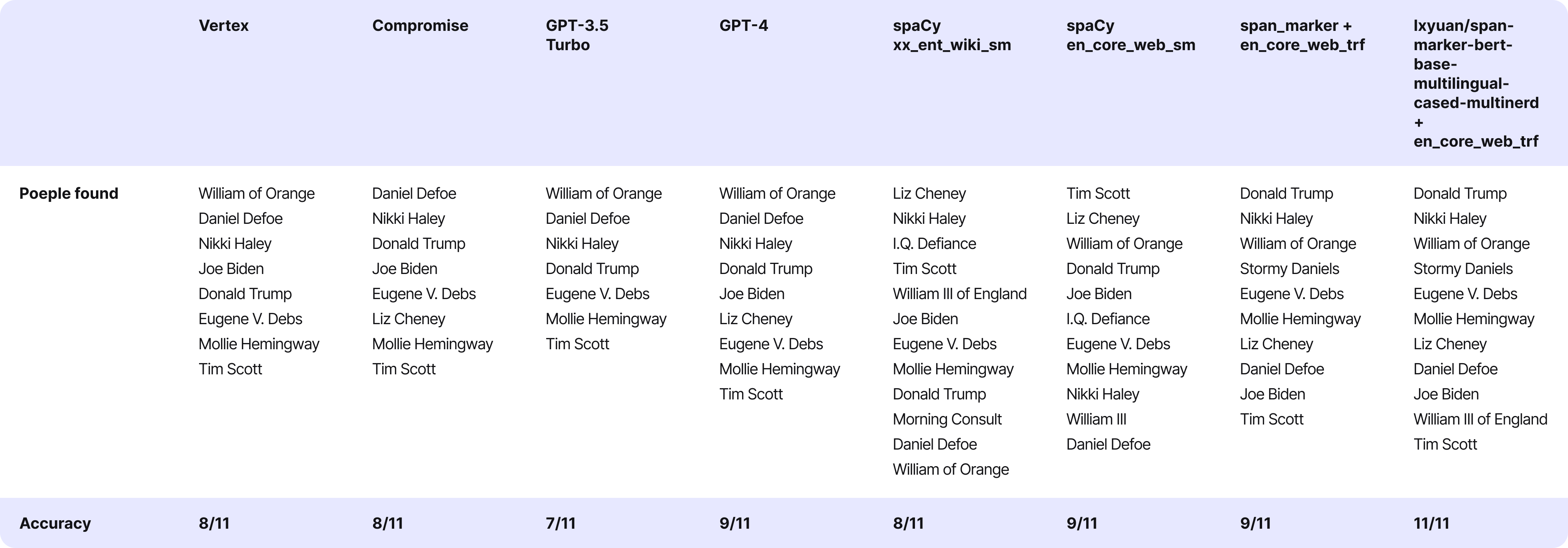
Conclusions
- Google Vertex carried out very effectively with each English and Croatian articles. Nonetheless, the Polish article handled soccer golf equipment as folks’s names.
- Compromise discovered roughly two-thirds of people within the article, even within the case of accessible articles. For the more difficult ones, it carried out even worse.
- GPT-3.5 carried out practically flawlessly, recognizing people in Polish and Croatian articles.
- What GPT-3.5 couldn’t accomplish, GPT-4 did. We might conclude the checks at this level, specializing in optimizing the immediate for GPT-4. Nevertheless, we couldn’t use this resolution for authorized causes.
- Relating to spaCy fashions, the preferred ones carried out reasonably effectively with English articles however poorly with non-English ones. Each multilingual fashions marked with ‘xx’ and English fashions marked with ‘en’ might return the identical individual twice. Filtering out duplicates proved fairly difficult.
Exams outcomes. Span Marker – the win within the names extraction class
The primary place goes to lxyuan/span-marker-bert-base-multilingual-cased-multinerd + en_core_web_trf.
The consumer determined based mostly on their tight enterprise and authorized necessities (e.g., maintaining every part on their tailored-made machine).
Essentially the most correct among the many fashions we examined and will use following consumer’s needs was lxyuan/span-marker-bert-base-multilingual-cased-multinerd, mixed with the spaCy mannequin en_core_web_trf. We all know it’s a mouthful. Moreover, we fine-tuned it via tokenization and different peculiar changes. This device dealt with English articles effectively however wanted some assist with Polish and Croatian.
Nevertheless, if you end up going through an identical selection, OpenAI is the most suitable choice in the meanwhile.
Gender detection. Obtainable options.
When deciding on a device for gender detection based mostly on names, our preliminary exploration centered on the preferred instruments accessible. We thought of:
- Gender API,
- Genderize.io,
- NamSor,
- Wiki-Gendersort.
Many of those instruments had their efficiency evaluated in research and comparisons to facilitate our decision-making course of:
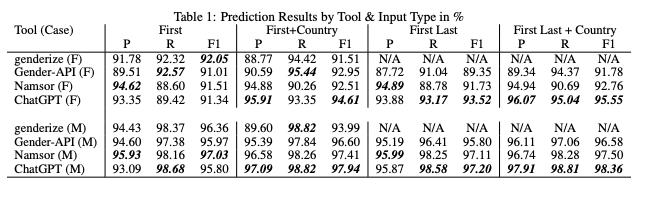
Supply: Gender inference
On this context, choosing a gender recognition device based mostly on names was comparatively simple.
After cautious consideration, we selected Genderize on account of its affordability and cheap accuracy. Genderize is sort of ten instances cheaper than different instruments, with solely barely much less accuracy! The worth-to-accuracy ratio was probably the most crucial issue for our wants (used as a backup in MVP).
Notably, the provision of a free demo account performed an important function within the preliminary phases of our utility. The demo account proved adequate to deal with the visitors and served as a cheap resolution for our wants.
Moreover, we thought of NameSor’s consumer, acknowledging its excessive accuracy. Nevertheless, as we delved deeper into our implementation, it turned obvious that Namesor was a much more costly choice.
We reevaluated the technique and made changes to our toolset. After a couple of weeks, our strategy advanced right into a extra refined one. We started by querying Google Data Graph after which Wikipedia. If an article a few particular individual was situated, we analyzed the pronouns to find out gender. In circumstances the place no related article was discovered, we seamlessly utilized Genderize as a dependable backup resolution. This mixture of instruments allowed us to boost the accuracy of our gender recognition course of whereas sustaining cost-effectiveness and effectivity.
Gender detection instruments value comparability
Let’s assume (100 000 articles * 5 names) / month
Within the case of OpenAI, we are going to apply optimization by querying all 5 names in a single API request.
| Identify | 1 request | 500k requests |
| Genderize | $0,00012 | $60 |
| NameSor | $0,0013 | $650 |
| GPT-4-0613 | $0,00513 | $513 (100k requests!) |
| Gender-API | $0,0008 | $399,95 |
Carried out options
Lastly, we selected Span Marker (hosted on ec2 with Nvidia graphics) solely after a couple of tweaks within the last code.
Within the code snipped above, perform extract_people:
- takes a textual content and a mannequin as enter,
- tokenizes the textual content into sentences and phrases utilizing NLTK,
- creates a knowledge dictionary with token data,
- creates a Dataset from the information dictionary,
- makes predictions on the dataset,
- filters entities to incorporate solely these labeled as ‘PER’ (individuals),
- codecs and returns the names of the extracted folks.
By testing, it turned out that sentence tokenization is useful.
Machine scaling and price comparability
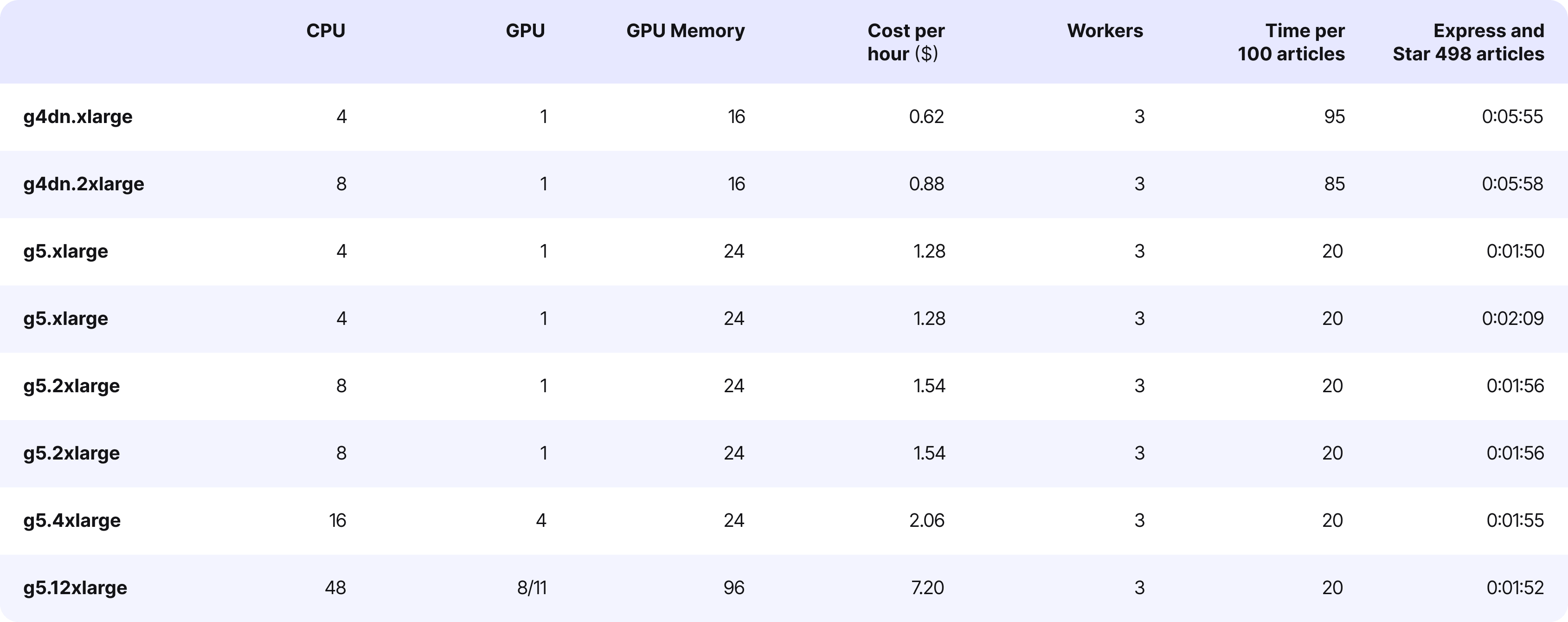
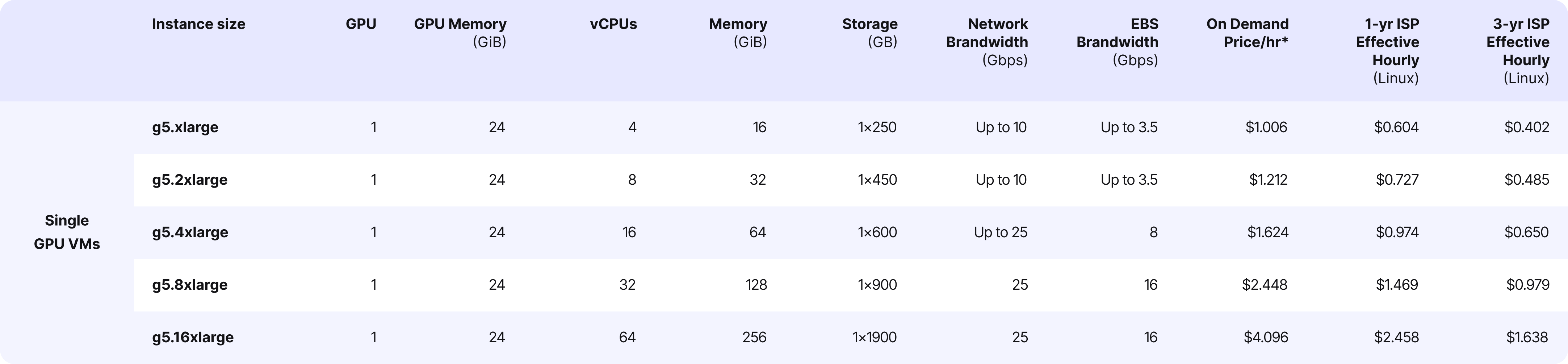
After the checks, we determined to decide on g5.xlarge with autoscaling enabled.
The g5.xlarge belongs to the G5 collection of cases in AWS EC2, explicitly designed for duties requiring important graphics processing energy. They’re ideally suited for machine studying, high-performance computing (HPC), and graphics rendering functions.
The largest situation with GPU cases is their value
In our case, the g5.xlarge prices one greenback per hour, which quantities to over 700 {dollars} a month, not together with scaling.
Now, let’s talk about scalability. We leveraged the built-in auto-scaling characteristic in EC2, which was based mostly on CPU load metrics. Within the occasion of elevated visitors, we routinely launched extra machines. AWS seamlessly directed the visitors to those machines based mostly on the CPU load metric.
Let’s assume 100,000 articles/month, the place one article equals 2000 characters. For Vertex and GPT it means 2000 tokens.
| Identify | 1 request | 100k requests |
| Vertex | $0,001 | $100 |
| Compromise | free
…however it’s worthwhile to pay for the infrastructure |
free
…however it’s worthwhile to pay for the infrastructure |
| GPT-3.5 | $0,0018 | $1800 |
| GPT-4 | $0,18 | $18000 |
| spaCy | $0,012 | $1200 |
Venture advantages
Within the case of this mission, we aimed to determine folks within the textual content and acknowledge their gender precisely. Automation accuracy and maintaining every part on a customized machine had been essential.
Therefore, the selection fell on spaCy + SpanMarker.
By altering Compromise to a Python mannequin, we might increase accuracy. Our checks confirmed that Compromise recognized half of the people, whereas Spanmarker discovered considerably extra cases.

Classes realized
Though this mission was performed and customised for a particular consumer, we gathered insights invaluable for anybody trying to implement identify extraction:
- OpenAI has probably the most correct instruments. Nevertheless, large worldwide companies require strict information safety and further necessities associated to native rules. So, there are circumstances the place you mustn’t use OpenAI.
- Many corporations concern utilizing OpenAI for his or her information safety and like to host one thing of their very own, e.g., LLaMA or Mistral.
- An OpenAI model is hosted in excessive isolation on Azure (OpenAI for Azure). This resolution is commonly utilized by corporations within the healthcare business exactly due to elevated safety.
- On this case research and different initiatives now we have performed, we see that GPT-4 is far more correct than GPT-3.5.
- GPT-4 is probably the most correct device however concurrently the costliest. So, if cash just isn’t a problem and accuracy is the primary precedence – go for it.
- Vertex is exact sufficient for its reasonably priced pricing.
- Generally, it’s value establishing your personal infrastructure and utilizing a ready-made mannequin for evaluation relatively than utilizing LLM. A extremely specialised pre-trained mannequin is healthier than a generic LLM
- The time-to-market utilizing GPT is way decrease than when utilizing ready-made fashions (on account of infrastructure, configuration, and so forth). You simply run GPT, and it really works.
- Organising your personal infrastructure comes with challenges (managing, updating, sustaining, and so forth.). Whereas it’s worthwhile on a bigger scale, it is probably not cost-effective on smaller-scale initiatives.
We elevate your initiatives with data-based AI experience!
From cutting-edge options to customized help, unlock the total potential of AI-driven innovation for your small business wants. E-book a free session with our specialists by clicking under.

Data-hungry Node.js developer. In his free time, Michał travels and engages in numerous sports activities disciplines, principally climbing.

Software program Architect skilled in backend applied sciences comparable to Node.js, cloud infrastructure, software program structure, and DevOps. Keenly eager about information engineering. One of many creators of Kakunin – our open-source framework for E2E testing. In his free time, Mariusz loves biking, machine studying, and 3D graphics.



















![How To Maximize Video Content Engagement on LinkedIn [Infographic]](https://newselfnewlife.com/wp-content/uploads/2025/09/Z3M6Ly9kaXZlc2l0ZS1zdG9yYWdlL2RpdmVpbWFnZS9saW5rZWRpbl92aWRlb190aXBzX2luZm8yLnBuZw.webp-120x86.webp)



{kind=link}